pytorch 101, part 2
原文地址,原文作者:Ayoosh Kathuria
翻译:zweien
Github 本文代码
本文我们将讨论如何使用PyTorch建立一个神经网络结构,并构建训练过程。我们将实现一个ResNet来对CIFAR-10数据集进行图像分类。
本文,我们将涉及
- 如何通过
nn.Module类来构建神经网络 - 如何通过
Dataset与Dataloader类来自定义数据输入管道与数据曾广 - 如何设置学习速率
- 通过训练一个ResNet基础分类器来实现对CIFAR-10数据集进行分类
预备知识
- 链式法则
- 对深度学习的基本理解
- PyTorch 1.0 +
- 本系列第一部分
一个简单的神经网络
在本教程中,我们将实现一个非常简单的神经网络 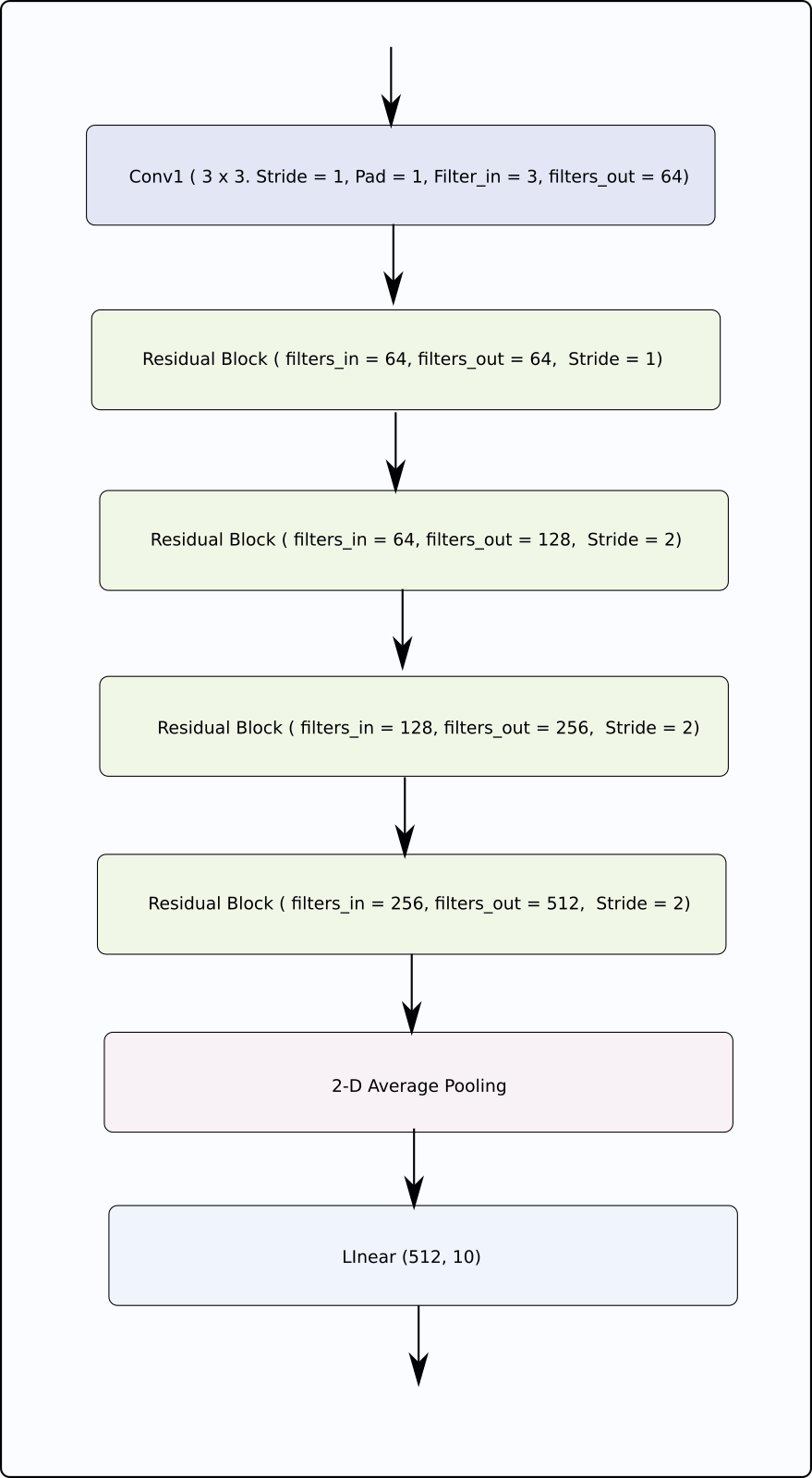 网络结构图
网络结构图
构建网络
torch.nn模块是 PyTorch 中构建神经网络的基石,该模块可以用来实现如全连接层、卷积层、池化层、激活函数等组件,也能通过实例化torch.nn.Module类来实现整个神经网络。(下文简称 nn.Module)
多个nn.Module对象可以连接起来形成一个更大的对象,对应到神经网络这就是层与层之间之间的连接。实际上,nn.Module 可以用来表示PyTorch 中的任意函数 f。
在使用时,nn.Module 类有两个方法需要用户重写
__init__函数,当实例化nn.Module类时该方法将被调用。在该方法中,你可以定义该层网络的参数,例如卷积网络中的卷积核的个数(filters)、卷积核尺寸(kernel size),dropout层的dropout概率等。forward函数,用来定义输入到输出的关系。该函数不需要显示的调用,使用时只需以函数调用方式调用nn.Module对象。
# Very simple layer that just multiplies the input by a number
class MyLayer(nn.Module):
def __init__(self, param):
super().__init__()
self.param = param
def forward(self, x):
return x * self.param
myLayerObject = MyLayer(5)
output = myLayerObject(torch.Tensor([5, 4, 3]) ) #calling forward inexplicitly
print(output)
另一个重要且广泛使用的类为nn.Sequential,通过该类我们可以将一个包含nn.Module对象的列表按照顺序组合起来,其返回值同样是nn.Module对象。当以一个输入值调用该对象时,将会按照初始化时的顺序依次执行所有nn.Module对象。
combinedNetwork = nn.Sequential(MyLayer(5), MyLayer(10))
output = combinedNetwork([3,4])
#equivalent to..
# out = MyLayer(5)([3,4])
# out = MyLayer(10)(out)
下面我们开始着手实现分类网络。我们将使用卷积层与池化层,还有残差结构(residual block)。
 残差结构
残差结构
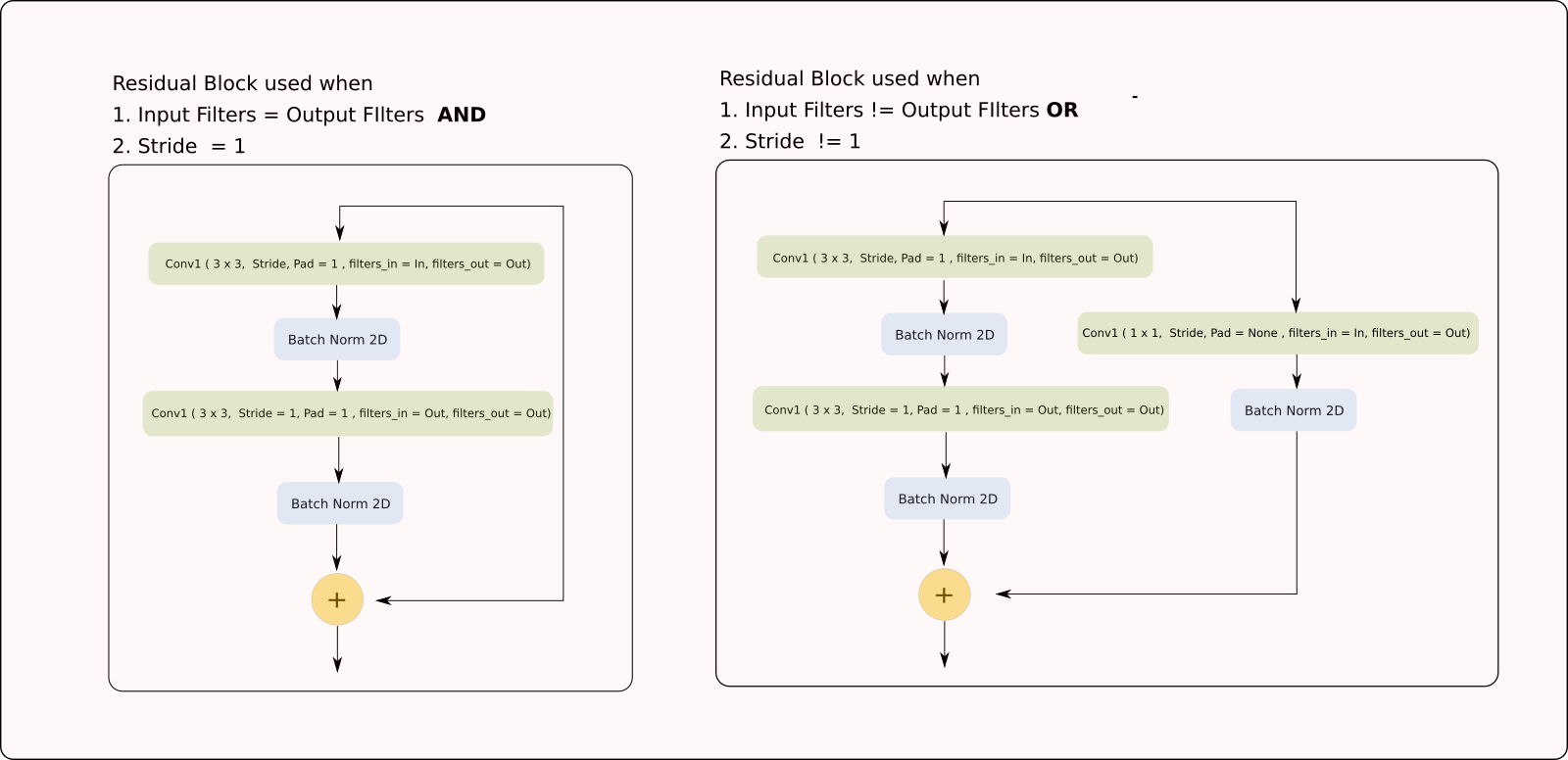
尽管PyTorch在nn.Module中提供了许多开箱即用的神经网络层,我们将自己定义残差结构。
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
# Conv Layer 1
self.conv1 = nn.Conv2d(
in_channels=in_channels, out_channels=out_channels,
kernel_size=(3, 3), stride=stride, padding=1, bias=False
)
self.bn1 = nn.BatchNorm2d(out_channels)
# Conv Layer 2
self.conv2 = nn.Conv2d(
in_channels=out_channels, out_channels=out_channels,
kernel_size=(3, 3), stride=1, padding=1, bias=False
)
self.bn2 = nn.BatchNorm2d(out_channels)
# Shortcut connection to downsample residual
# In case the output dimensions of the residual block is not the same
# as it's input, have a convolutional layer downsample the layer
# being bought forward by approporate striding and filters
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(
in_channels=in_channels, out_channels=out_channels,
kernel_size=(1, 1), stride=stride, bias=False
),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = nn.ReLU()(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = nn.ReLU()(out)
return out
正如上述代码所示,我们通过__init__函数定义了结构组件。在forward函数中,我们将这些定义的组件串起来,由输入得到输出。
下面,我们定义完整的网络。
class ResNet(nn.Module):
def __init__(self, num_classes=10):
super(ResNet, self).__init__()
# Initial input conv
self.conv1 = nn.Conv2d(
in_channels=3, out_channels=64, kernel_size=(3, 3),
stride=1, padding=1, bias=False
)
self.bn1 = nn.BatchNorm2d(64)
# Create blocks
self.block1 = self._create_block(64, 64, stride=1)
self.block2 = self._create_block(64, 128, stride=2)
self.block3 = self._create_block(128, 256, stride=2)
self.block4 = self._create_block(256, 512, stride=2)
self.linear = nn.Linear(512, num_classes)
# A block is just two residual blocks for ResNet18
def _create_block(self, in_channels, out_channels, stride):
return nn.Sequential(
ResidualBlock(in_channels, out_channels, stride),
ResidualBlock(out_channels, out_channels, 1)
)
def forward(self, x):
# Output of one layer becomes input to the next
out = nn.ReLU()(self.bn1(self.conv1(x)))
out = self.stage1(out)
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
out = nn.AvgPool2d(4)(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
输入格式
定义好网络结构,下面考虑网络的输入。在深度学习领域,我们将遇到多种输入格式,如图像、声音、高维结构数据。
我们将处理的数据为图像,一般来说,在PyTorch中,输入数据的第一维度是批(batch)。
对于图像的来说输入数据格式为 [B C H W],其中 B 为批大小,C为通道,H为图像高,W为宽。
目前网络的输出并没有实际意义,因为我们使用的是随机网络参数(weights)。下面我们开始训练该神经网络。
加载数据
我们将使用torch.utils.data.Dataset与torch.utils.data.Dataloader类来加载数据。
首先在代码相同目录中下载 CIFAR-10 数据集,在终端中切换到代码目录,执行如下命令
wget http://pjreddie.com/media/files/cifar.tgz
tar xzf cifar.tgz
在 macOS 中可以使用 curl命令,在windows中可以手动下载该数据集。
我们开始读取CIFAR数据集中的标签。
data_dir = "cifar/train/"
with open("cifar/labels.txt") as label_file:
labels = label_file.read().split()
label_mapping = dict(zip(labels, list(range(len(labels)))))
我们使用 PIL 库来读取图片数据。在读取数据前,我们首先实现预处理函数,包含以下步骤
- 以0.5概率,随机水平翻转
- 利用数据集的均值与标准差进行正则化(Normalise)处理
- 将数据从
W H C调整为C H Wdef preprocess(image): image = np.array(image) if random.random() > 0.5: image = image[::-1,:,:] cifar_mean = np.array([0.4914, 0.4822, 0.4465]).reshape(1,1,-1) cifar_std = np.array([0.2023, 0.1994, 0.2010]).reshape(1,1,-1) image = (image - cifar_mean) / cifar_std image = image.transpose(2,1,0) return image
通常来说,PyTorch 中提供了两个类来构建加载数据的管道(pipelines)。
torch.data.utils.dataset,下文简写为datasettorch.data.utils.dataloader,下文简写为dataloader
torch.utils.data.dataset
dataset类加载数据并返回用来迭代的生成器(generator),该类也能结合数据增广来实现数据管道。
创建dataset对象,需要重写以下三个函数
__init__函数,定义数据集所需元素,最重要的是数据的位置。你也可以定义想要使用的数据增广功能。__len__函数,返回数据集的长度。__getitem__函数,该函数输入参数为 indexi,返回一个样本。该函数将在训练循环中每次迭代时调用。
下面代码实现了我们自定义的dataset
class Cifar10Dataset(torch.utils.data.Dataset):
def __init__(self, data_dir, data_size = 0, transforms = None):
files = os.listdir(data_dir)
files = [os.path.join(data_dir,x) for x in files]
if data_size < 0 or data_size > len(files):
assert("Data size should be between 0 to number of files in the dataset")
if data_size == 0:
data_size = len(files)
self.data_size = data_size
self.files = random.sample(files, self.data_size)
self.transforms = transforms
def __len__(self):
return self.data_size
def __getitem__(self, idx):
image_address = self.files[idx]
image = Image.open(image_address)
image = preprocess(image)
label_name = image_address[:-4].split("_")[-1]
label = label_mapping[label_name]
image = image.astype(np.float32)
if self.transforms:
image = self.transforms(image)
return image, label
在__getitem__函数中同样实现了从图像文件名中提取标签类别。
Dataset类允许我们采用惰性数据加载原则(lazy data loading principle),这意味着我们并非将所有数据读入内存,而是当需要时进行读取(当__getitem__被调用时)。
当你通过Dataset类创建对象时,你可以像python中可迭代对象那样操作它,在每次迭代中,__getitem__以参数i被调用。
数据增广 Data Augmentations
在上述 __init__函数中,传入了参数transforms,它可以是实现数据增广的任何python 函数。尽管你可以在预处理函数部分实现这一功能,在__getitem__中实现仅仅是本文的代码实现风格。
此处的数据增广可以实现为函数或者类,你仅需确保在__getitem__中可以调用他们。
我们有许多外部库来实现各种数据增广功能。
针对我们的需求,torchvision 库提供了大量的预先定义好的transforms,并且组合起来实现更大的transform。但是本文我们仅限于讨论 PyTorch 部分。
torch.utils.data.Dataloader
Dataloader 类可实现以下功能:
- 将数据批化(batching)
- 将数据打乱(shuffling)
- 通过线程(threads)同时读取多个数据
- 预获取(prefetching)数据,当GPU处理当前批数据时,
Dataloader可以预先将下一批数据读入内存,这将加速训练过程。
你可以通过Dataset对象来实例化一个Dataloader,这将就能以相同的方式对Dataloader对象进行迭代。
不同的是,你可以设置多种参数实现对循环的控制,例如
trainset = Cifar10Dataset(data_dir = "cifar/train/", transforms=None)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testset = Cifar10Dataset(data_dir = "cifar/test/", transforms=None)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=True, num_workers=2)
此处transet与trainloader对象都是生成器,可以使用如下方式进行迭代
for data in trainloader: # or trainset
img, label = data
然而,Dataloader 类比Dataset 类使用起来更加方便。在每次迭代中,Dataset只会返回由 __getitem__返回的结果,Dataloader将进行更多的处理
- 注意到
trainset的__getitem__方法返回一个3x32x32的numpy array,Dataloader返回批数据128x3x32x32。(因为batch_size=128) __getitem__方法返回numpy array,而Dataloader类自动将数据转换为Tensor- 即使
__getitem__返回非数值的数据,Dataloader仍然将返回长度为B的list或tuple。假设__getitem__返回一个字符串,如图像标签,如果我们初始化Dataloader时设置 batch=128,在每次迭代中,我们将得到一个长度为128的字符串组成的tuple。
考虑到预加载、多线程等功能,Dataloader总是我们优先的选择。
训练(training)与评估(evaluation)
在开始编写训练循环前,我们需要决定一些超参数(hyperparameters)与优化算法。PyTorch 在torch.optim模块中给我们提供了许多方便使用的优化算法。
torch.optim
torch.optim模块提供了许多功能组件如
- 多种优化算法(如
optim.SGD,optim.Adam等) - 学习率策略(
optim.lr_scheduler) - 对不同参数使用不同学习率(本文将不会涉及这一部分)
在本文中我们将使用交叉熵损失函数(cross entropy loss),动量(momentum)型随机梯度(SGD)优化算法,并且使用学习率策略在150与200 epoch时乘以衰减系数0.1
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #Check whether a GPU is present.
clf = ResNet()
clf.to(device) #Put the network on GPU if present
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(clf.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[150, 200], gamma=0.1)
代码的第一行的含义是,如果存在GPU,device将设置为cuda:0,否则将设为 CPU。
当我们初始化网络时,默认情况将使用 CPU,clf.to(device)将网络移动到 GPU (如果存在的话)。我们将在接下来的教程中涉及如何使用多块 GPUs。我们同样可以使用clf.cuda(0)将网络clf移动到GPU 0。
criterion 是 nn.CrossEntropy类型的对象,实现交叉熵损失函数,它继承了nn.Module类。
然后我们定义optim.SGD类型的变量 optimizer,optim.SGD的第一个参数是clf.parameters()。nn.Module对象的parameters()函数返回网络的参数(nn.Parameter对象),我们将在下一部分PyTorch高级功能部分学习该类的使用。目前,只需将它看成包含可学习(learnable)参数的list。clf.parameters()即为我们定义的神经网络的参数。
正如代码所示,我们将调用optimizer的step()。当 step() 被调用时,optimizer 将通过梯度更新 clf.parameters() 中的 Tensor。梯度通过Tensor里grad属性来获取。
一般来说,优化器如SGD、Adam、RMSprop的第一个参数是需要更新的网络参数,剩余的参数定义了不同的超参数。
scheduler,定义了优化器的不同超参数策略。optimizer 被用来实例化 scheduler。当我们每次调用scheduler.step(),它将更新超参数。
实现循环
我们将训练 200 轮(epoch),你可以增加训练轮数。这将花些训练时间,本教程的目的是展示PyTorch 的工作原理,并不是达到最优精度。
在每轮,我们将评估分类精度。
for epoch in range(10):
losses = []
scheduler.step()
# Train
start = time.time()
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad() # Zero the gradients
outputs = clf(inputs) # Forward pass
loss = criterion(outputs, targets) # Compute the Loss
loss.backward() # Compute the Gradients
optimizer.step() # Updated the weights
losses.append(loss.item())
end = time.time()
if batch_idx % 100 == 0:
print('Batch Index : %d Loss : %.3f Time : %.3f seconds ' % (batch_idx, np.mean(losses), end - start))
start = time.time()
# Evaluate
clf.eval()
total = 0
correct = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = clf(inputs)
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum()
print('Epoch : %d Test Acc : %.3f' % (epoch, 100.*correct/total))
print('--------------------------------------------------------------')
clf.train()
这是一大段代码,我并没有将其分为小段代码,以防止破坏连续性。下面将解释上述代码中的重要部分。
我们首先在每轮的开始部分调用scheduler.step(),以保证optimizer使用正确的学习率。
在循环中,第一部分是将input和target移动到GPU上,必须确保使用的是相同的device,负责PyTorch将抛出异常。
注意到,我们在正向过程前调用optimizer.zero_grad(),这是因为叶Tensor(网络参数)将保留上一步的梯度值,如果loss的backward再次被调用,新梯度将累加到上一步迭代的梯度值上去,即参数的grad属性。这一特性在使用RNN是非常有用,但是目前我们需要在每次更新参数前将梯度清零。
在进行评估时,我们使用了torch.no_grad上下文管理器,这样就不会涉及计算图的部分,可参阅本系列的第一部分。
还有一点需要注意的是,在评估前调用clf.eval(),评估之后再次调用clf.train()。PyTorch中的模型拥有两个状态,使用eval()与train()进行切换,在使用如 Batch Norm 层时(训练中的批统计量 vs 推断中总体统计量)、Dropout层等在训练与推断中会产生差别。eval告诉模型将这些层设置成推断模式,而train则设置成训练模式。
结论
本文介绍了一个基础的图像分类器,尽管这只是一个开始,我们已经涉及了使用PyTorch构建深度神经网络的大体框架。
在本系列的下一部分,我们将考虑PyTorch中的高级部分,包括设计更复杂的网络结构、针对不同参数设计不同的学习率等。